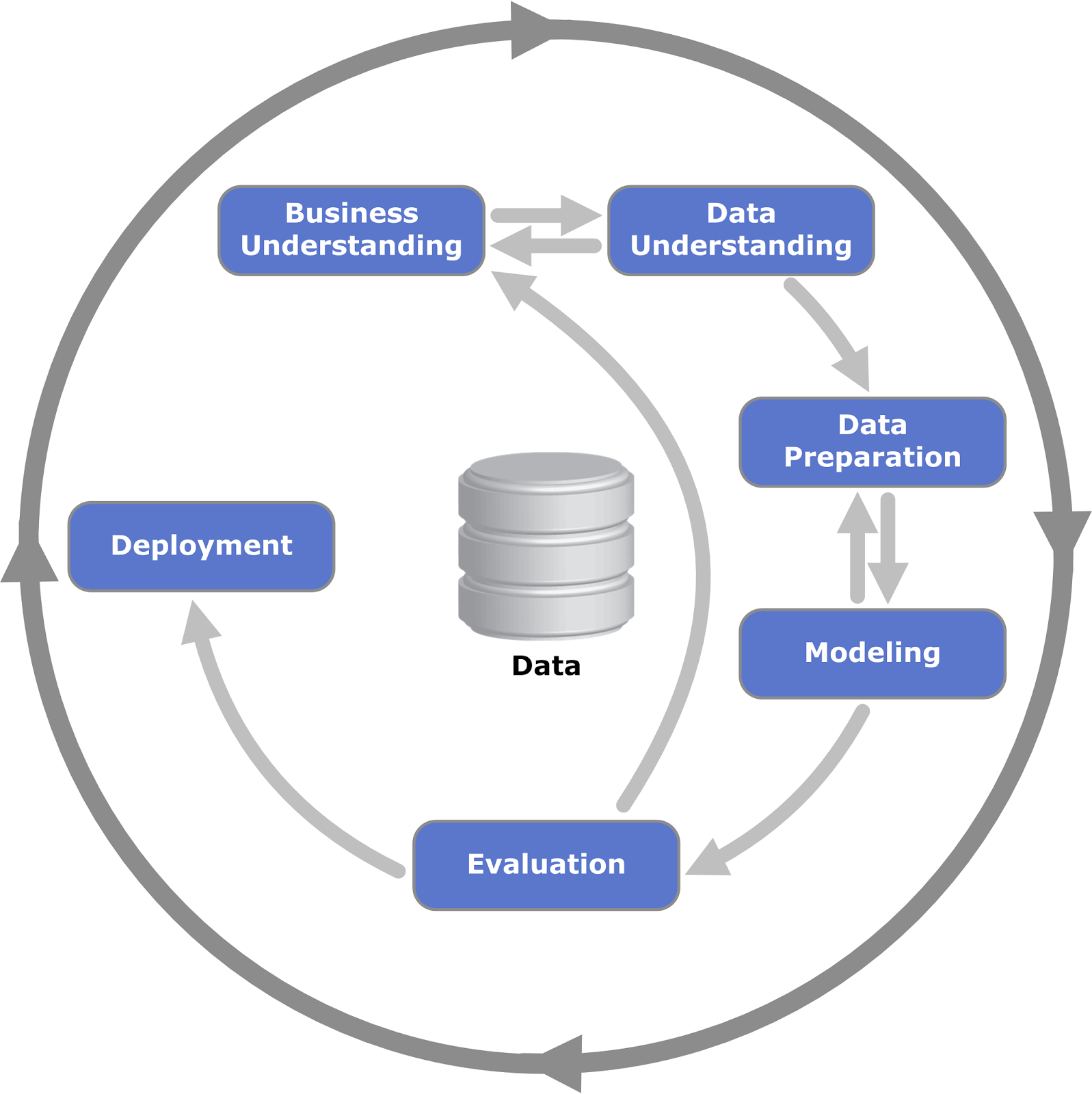
FASE DE COMPRENSIÓN DEL MODELO DE NEGOCIO
En esta fase se recolecta la información corporativa e institucional que
permita comprender el modelo de negocios e identificar los objetivos
estratégicos de la organización. Se consultan fuentes como el organigrama
empresarial, el diagrama de procesos, el manual de procedimientos, el
portafolio de servicios y todas aquellas que suministren información que
permita comprender la estructura y el funcionamiento de los procesos que
tiene la organización.
El conocimiento que se adquiere del funcionamiento de la organización
debe permitir identificar claramente los objetivos estratégicos del negocio,
para que el diseño del cubo de datos se oriente hacia el alcance de estos.
El análisis obtenido en esta fase se consolida en un documento llamado
“Dominio del negocio de la organización” donde se realiza la descripción
del modelo de negocio, se establecen los objetivos estratégicos de la
organización y se explica la estructura de la organización.
FASE DE LEVANTAMIENTO DE REQUERIMIENTOS
En esta fase se recolectan datos y se someten a análisis con el fin de
transformarlos en información que permita identificar las necesidades
del modelo de negocio de la organización, esto implica estudiar las
interacciones que se dan entre los datos y los procesos que se llevan a
cabo en cada una de las áreas de la organización.
Para el levantamiento de la información se pueden aplicar algunas de las
siguientes técnicas:
• Introspección u observación directa.
• Entrevistas y cuestionarios.
• Lluvia o tormenta de ideas.
• Storyboards.
• Etnografía o análisis organizacional.
La información obtenida durante el levantamiento de requerimientos debe
permitir identificar los interrogantes que el cubo de datos debe solucionar
para cada área de negocio que desea utilizarlo, esto permitirá recolectar
los datos correctos e interpretar adecuadamente los resultados.
El análisis obtenido en esta fase se consolida en un documento llamado
“Requerimientos del cubo de datos” en donde se consignan las preguntas que responderá el cubo de datos junto con los aspectos positivos y
negativos que este tendrá en cada área de negocio.
FASE DE RECOLECCIÓN DE LOS DATOS
En esta fase se recolectan los datos desde los sistemas fuentes para realizar
sobre ellos una descripción cualitativa y cuantitativa, posteriormente se
procede a determinar sus propiedades y verificar la calidad de los mismos.
Esta fase consta de las siguientes etapas:
1. Identificación de las fuentes de los datos: se identifican los
sistemas fuentes que contienen los datos y se extraen para posteriormente
adecuarlos, es importante tener en cuenta que los datos pueden residir en
diversos tipos de sistemas, a continuación mencionamos algunos de los
más típicos dentro de las organizaciones:
• Hojas de cálculo
• Bases de datos
• Archivos estadísticos
• Sistemas de información empresarial (ERP, ERP, FRM, HRM, MRP,
SCM)
• Archivos documentales físicos y digitales.
Luego de extraer los datos se elabora un informe que se denomina “reporte
de recolección de datos” el cual contiene la lista de los datos extraídos,
su localización, las técnicas utilizadas para su recolección y los problemas
que se presentaron durante este proceso, así como la forma en que fueron
resueltos.
2. Descripción de los datos: se realiza la descripción de los
datos extraídos desde los sistemas fuentes con el fin de establecer sus
características y métricas de la siguiente forma:
• Descripción cualitativa: se refiere a las cualidades relevantes de
los datos que pueden ser descritas utilizando: Significado de la tabla
que contiene los datos, descripción de la campo que contiene el dato y
descripción del tipo de campo.
• Descripción cuantitativa: se refiere a las métricas que pueden ser
calculadas u obtenidas del volumen de datos, como: Número de campos
por tabla, número de registros por tabla y número de relaciones.
• La información recolectada de los datos se consigna en un informe
denominado “reporte de la descripción de datos”
3. Exploración de los datos: Se procede a explorar los datos que
han sido extraídos desde los sistemas fuentes, con el fin de encontrar
una estructura general para los datos “homogeneidad” y de identificar
problemas “datos paralizantes” que puedan ocurrir durante las fases
siguientes. Las novedades encontradas en esta fase se registran en un
documento denominado “Reporte de exploración de datos”.
4. Verificación de la calidad y consistencia de los datos: Se
efectúan verificaciones sobre los datos, que permitan asegurar la
consistencia de los valores individuales de los campos, la cantidad y
distribución de los valores nulos y la corrección de valores fuera de rango
que puedan constituirse en elementos que alteren el resultado del proceso.
Los resultados de esta fase se consignan en un documento que lleva por
nombre “Reporte de calidad de datos”
FASE DE PREPARACIÓN DE DATOS
Finalizada la fase de recolección de los datos, se procede al alistamiento
de los datos para la posterior construcción del cubo de datos. La fase de
preparación de datos consta de las siguientes etapas:
1. Selección de datos: se seleccionan los datos de la fase anterior,
utilizando como criterio de selección la calidad de los datos en cuanto a
completitud y consistencia.
2. Limpieza de los datos: se optimiza la calidad de los datos mediante
la aplicación de técnicas que eliminen datos paralizantes, valores fuera de
rango y caracteres extraños; algunas de estas técnicas son: normalización
de datos, discretización de campos numéricos y tratamiento de valores
ausentes.
3. Estructuración de los datos: se realizan operaciones de
alistamiento sobre los datos, las cuales generan nuevos atributos a partir
de los ya existentes y transforman los valores de los ya existentes.
4. Integración de los datos: se crean nuevas estructuras que unifican
los datos, para esto se fusionan tablas que contengan atributos diferentes
de un mismo objeto y se generan nuevos campos y registros que resuman
los actuales.
5. Formateo de los datos: se realizan transformaciones sintácticas
de los datos sin modificar su significado, esto se consigue mediante la
reordenación o ajuste de los campos y registros de las tablas; también se
eliminan comas, tabuladores, caracteres especiales, máximos y mínimos
para las cadenas de caracteres.
FASE DE MODELADO DEL CUBO DE DATOS
En esta fase se identifican las dimensiones, métricas y tablas de hecho
que constituirán el cubo de datos. Algunos de los aspectos para identificar
los atributos de estos elementos son:
• Atributos de métrica: son aquellos atributos que permiten establecer
un valor cuantitativo sobre los datos.
• Atributos de dimensión: son todos los atributos que aportan
cualidades a los datos.
• Datos multidimencionales: son los datos que no pueden modelarse
como atributos de dimensión o de medida.
• Atributos de la(s) tabla(s) de Hecho(s): Para identificar estos
atributos hay que prestar especial atención a las tabulaciones cruzadas
puesto que estas son sumatorias que no están guardas directamente en
las tablas del modelo relacional, si no que son el resultado de operaciones
aritméticas que se obtienen de disponer de distintas formas los atributos
de métrica y de dimensión.
Se debe construir el cubo de datos, teniendo en cuenta el número de
dimensiones y de tablas de hecho que se hayan identificado. Para esto hay
que seleccionar entre los siguientes modelos de datos el más adecuado
para construir el cubo:
Modelo estrella
Modelo copo de nieve
Modelo
constelación.
La estructura dimensional propuesta para el cubo de datos debe resolver
las preguntas que se han planteado en el documento de requerimientos.
No hay un modelo mejor que otro, cada uno responde a un análisis
particular del cual depende su precisión y validez.
FASE DE IMPLEMENTACIÓN DEL CUBO DE DATOS
En esta la fase se construye el modelo físico del cubo de datos el cual se
realiza de la siguiente forma:
1. Crear las tablas de cada una de las dimensiones del cubo con sus
respectivos atributos y llaves primarias.
2. Después se construye(n) la(s) tabla(s) de hecho(s) con sus campos,
llaves primarias y relaciones que se han identificado en el modelo
seleccionado.
FASE DE CONSTRUCCIÓN DEL VISUALIZADOR DEL CUBO DE
DATOS
La fase de construcción del visualizador del cubo de datos puede ser
abordada de las siguientes formas:
• Construcción una vista en la base de datos
• Desarrollo de una aplicación en un lenguaje de programación
específico
• Utilización de una herramienta de uso específico existente
• Creación del visualizador en una herramienta de uso general como
una hoja de cálculo
En esta fase se busca que el usuario obtenga una interpretación más
intuitiva y rápida de la información que le puede suministrar el cubo de
datos.
La forma en que se aborde la construcción del visualizador del cubo de
datos depende del tamaño del cubo, el tiempo y los recursos disponibles
para ello.
Integrantes:
Leidys Jiménez
Claudía Viloria
Deisy Cataño